
请在文末下载附件
一、背景
最大连续次数或者是最大连续子序列问题,在DAX中如何快速计算呢?
思路
1、N-1:按照INDEX错位
2、START:连续第一出现INDEX
3、END:最后一次出现的INDEX下一位
4、END-START刚好等于连续出现的次数
5、T8为结果
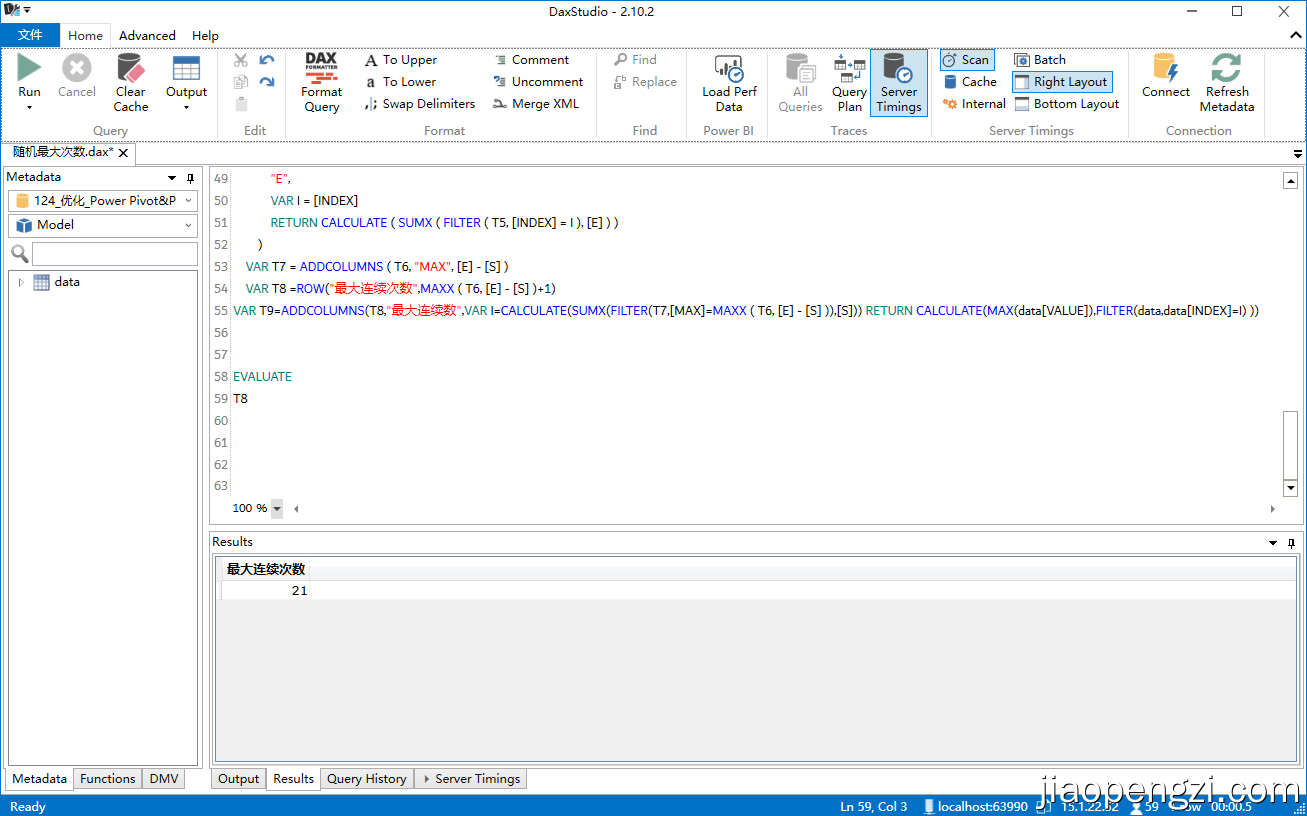
10万条数据只需要不到0.2秒,速度相当可观了,已能解决大部分实际工作场景。

二、数据源

为了方便展示,设定了7到28,1出现最大次数28-7=21;拿到文件可以自行修改再验证。
三、上DAX
分步DAX
DEFINE
VAR T0 =
ADDCOLUMNS (
DATA,
"N-1",
VAR I0 = DATA[INDEX]
VAR V0 =CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I0- 1 ) )
RETURN
V0,
"START",
VAR I1 = DATA[INDEX]
VAR V1 =CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I1 - 1 ) )
RETURN
IF ( V1 <> [VALUE]&& V1 = 0, [INDEX] ),
"END",
VAR I2 = DATA[INDEX]
VAR V2 = CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I2 - 1 ) )
RETURN
IF ( V2 <> [VALUE]&& V2 = 1, [INDEX] )
)
VAR T1 =
ADDCOLUMNS (
DATA,
"START",
VAR I1 = DATA[INDEX]
VAR V1 =CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I1 - 1 ) )
RETURN
IF ( V1 <> [VALUE]&& V1 = 0, [INDEX] ),
"END",
VAR I2 = DATA[INDEX]
VAR V2 = CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I2 - 1 ) )
RETURN
IF ( V2 <> [VALUE]&& V2 = 1, [INDEX] )
)
VAR T2 =SELECTCOLUMNS ( FILTER ( T1, [START] > 0 ), "START", [INDEX] )
VAR T3 = SELECTCOLUMNS ( FILTER ( T1, [END] > 0 ), "END", [INDEX] )
VAR T4 =SUBSTITUTEWITHINDEX (
ADDCOLUMNS ( T2, "S", [START] )
, "INDEX"
, T2
,[START]
, ASC)
VAR T5 =SUBSTITUTEWITHINDEX (
ADDCOLUMNS ( T3, "E", [END] )
, "INDEX"
, T3
, [END]
, ASC )
VAR T6 =ADDCOLUMNS (
T4,
"E",
VAR I = [INDEX]
RETURNCALCULATE ( SUMX ( FILTER ( T5, [INDEX] = I ), [E] ) )
)
VAR T7 = ADDCOLUMNS ( T6, "MAX", [E] - [S] )
VAR T8 =ROW ( "最大连续次数", MAXX ( T6, [E] - [S] ) )
EVALUATE
T8分步说明
1、T1错位找出1开始的index和结束的index

2、T4找到开始index,使用SUBSTITUTEWITHINDEX建立新index

3、T5找到结束index,使用SUBSTITUTEWITHINDEX建立新index
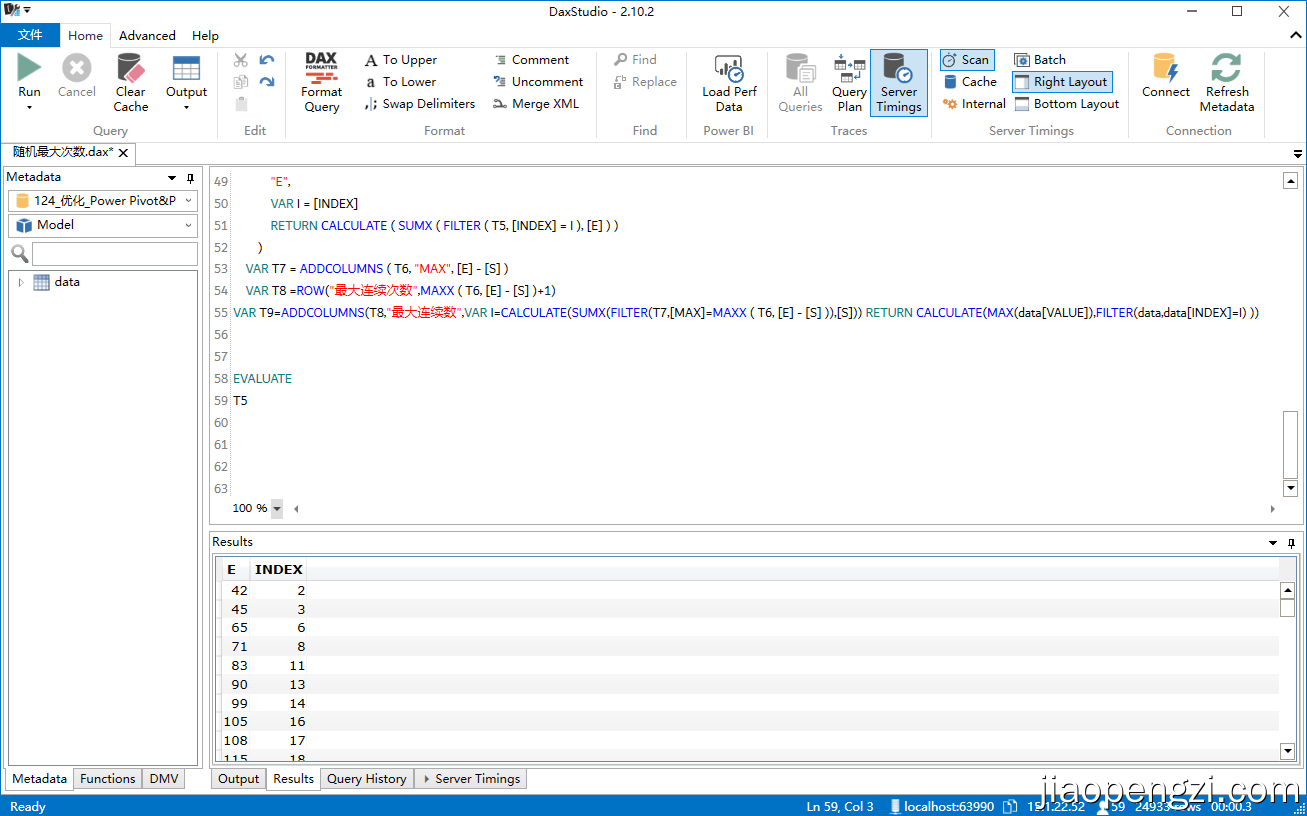
5、T7通过新index把1出现次数首尾老INDEX放到一起,实现“END-START刚好等于连续出现的次数”。
这里注意新老INDEX,本来可以给新的字段名,难得想名字了,使用的时候要注意有点绕。
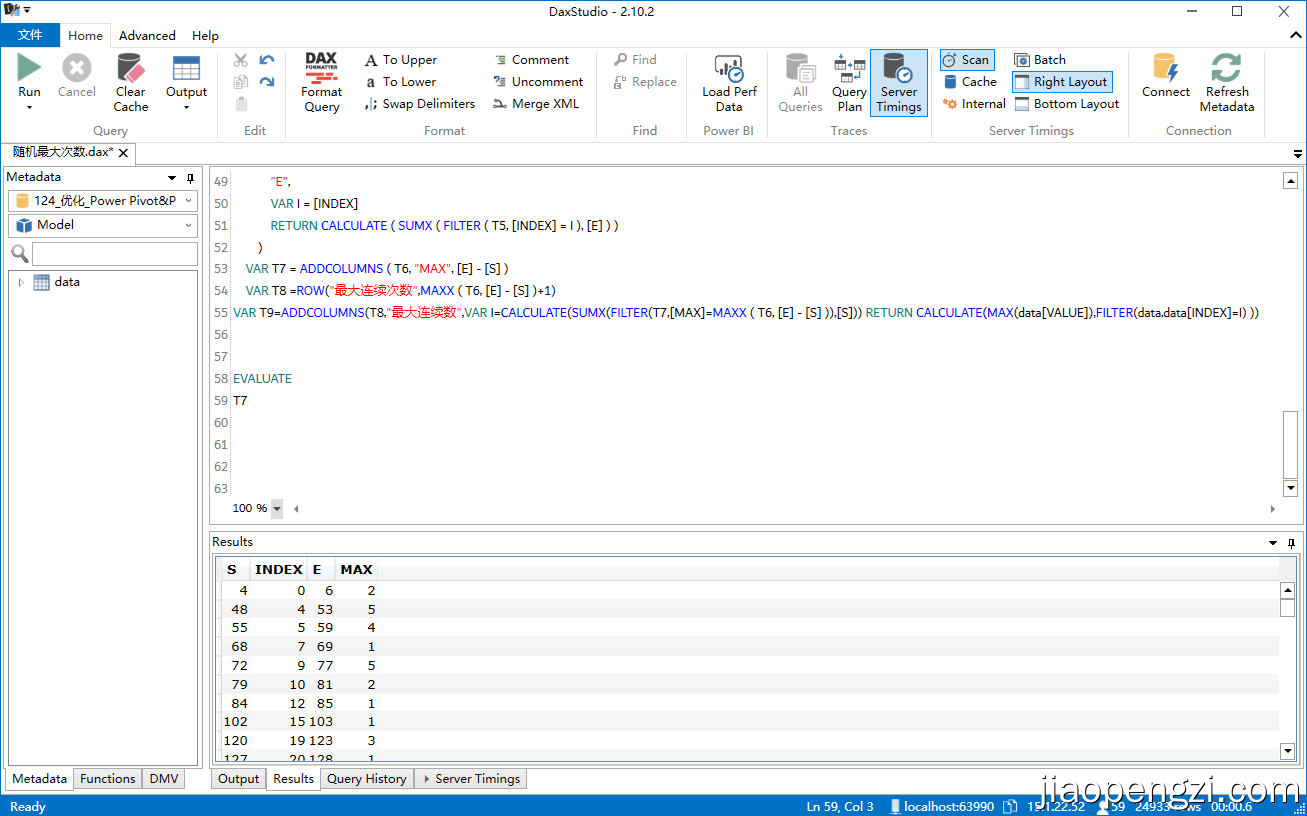
6、最终度量值:最大连续次数
最大连续次数:=
VAR T1 =
ADDCOLUMNS (
DATA,
"START",
VAR I1 = DATA[INDEX]
VAR V1 =CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I1 - 1 ) )
RETURN
IF ( V1 <> [VALUE] && V1 = 0, [INDEX] ),
"END",
VAR I2 = DATA[INDEX]
VAR V2 = CALCULATE ( SUM ( DATA[VALUE] ), FILTER ( DATA, DATA[INDEX] = I2 - 1 ) )
RETURN
IF ( V2 <> [VALUE] && V2 = 1, [INDEX] )
)
VAR T2 =SELECTCOLUMNS ( FILTER ( T1, [START] > 0 ), "START", [INDEX] )
VAR T3 = SELECTCOLUMNS ( FILTER ( T1, [END] > 0 ), "END", [INDEX] )
VAR T4 =SUBSTITUTEWITHINDEX (
ADDCOLUMNS ( T2, "S", [START] )
, "INDEX"
, T2
,[START]
, ASC)
VAR T5 =SUBSTITUTEWITHINDEX (
ADDCOLUMNS ( T3, "E", [END] )
, "INDEX"
, T3
, [END]
, ASC )
VAR T6 =ADDCOLUMNS (
T4,
"E",
VAR I = [INDEX]
RETURN CALCULATE ( SUMX ( FILTER ( T5, [INDEX] = I ), [E] ) )
)
RETURN
MAXX ( T6, [E] - [S] )四、总结
1、本案例中使用INDEX错位,从结构上去优化计算效率;
2、对SUBSTITUTEWITHINDEX的熟悉;
3、类似案例要多思考计算的本质。
by 焦棚子
请点击【立即购买】或者【升级VIP】获得案例附件。




评论