
请在文末下载附件
一、问题
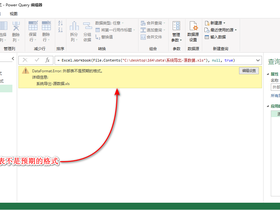
pq在用 Excel.Workbook 读取一些Excel早期版本(.xls后缀)的文件时候,报错:DataFormat.Error: 外部表不是预期的格式。
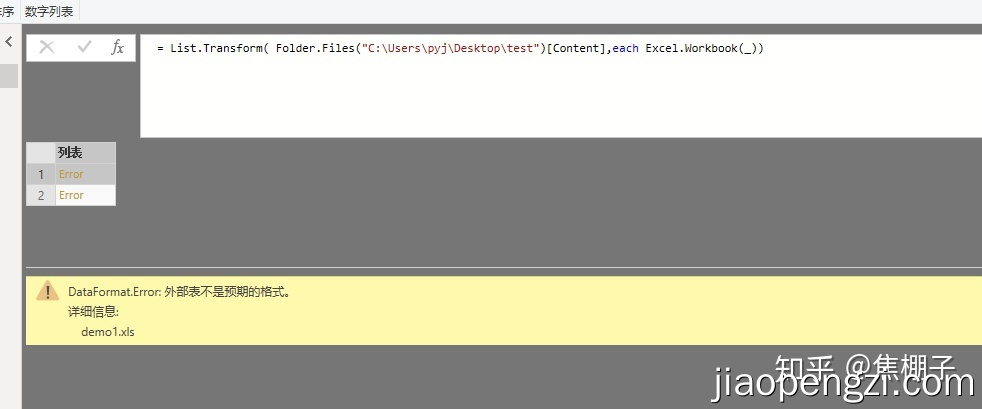
二、解决方案
方案1
如果文件少可以另存为.xlsx版本即可用 Excel.Workbook 读取,也有批量xls转xlsx的工具(可自行搜索)
方案2
在不更改文件版本的情况下,可以用 R.Execute 调用R脚本读取也是非常简单的。
情况1:单个文件
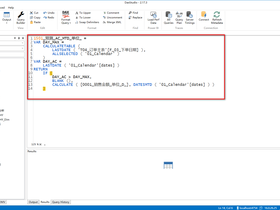
let
源 = R.Execute(
"library(xlsx)
data <- read.xlsx(file = 'C:\\Users\\pyj\\Desktop\\test\\demo1.xls',1, startRow=5,colIndex=c(1),header = FALSE,encoding = 'UTF-8')")
in
源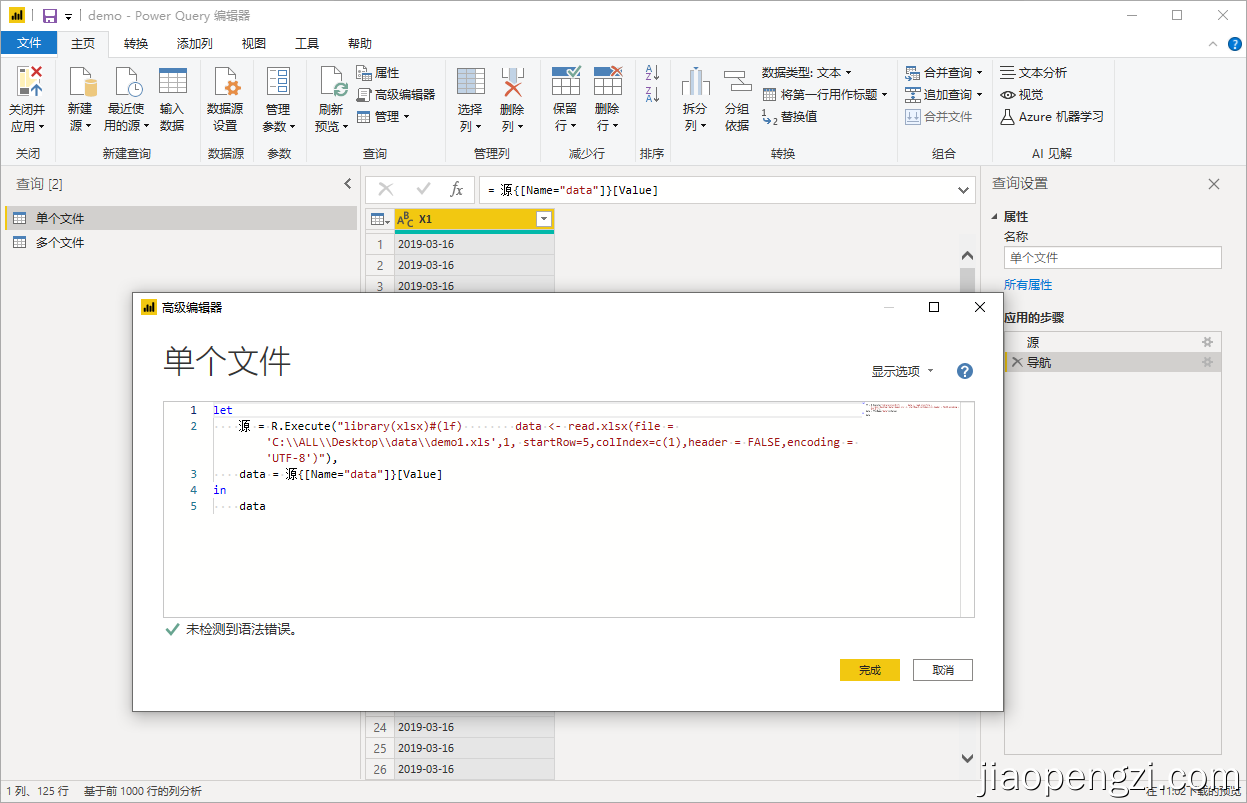
情况2:多个文件
let
源 = R.Execute(
"library(xlsx)
#设定文件夹路径
setwd('C:\\Users\\pyj\\Desktop\\test')
filenames <- dir()
#数据框
data <- data.frame()
for (i in filenames){
#循环file
path <- paste0(getwd(),'\\',i)
# 读取并合并数据
data <- rbind(data,read.xlsx(file = path,1, startRow=5,colIndex=c(1),header = FALSE,encoding = 'UTF-8'))}"
)
in
源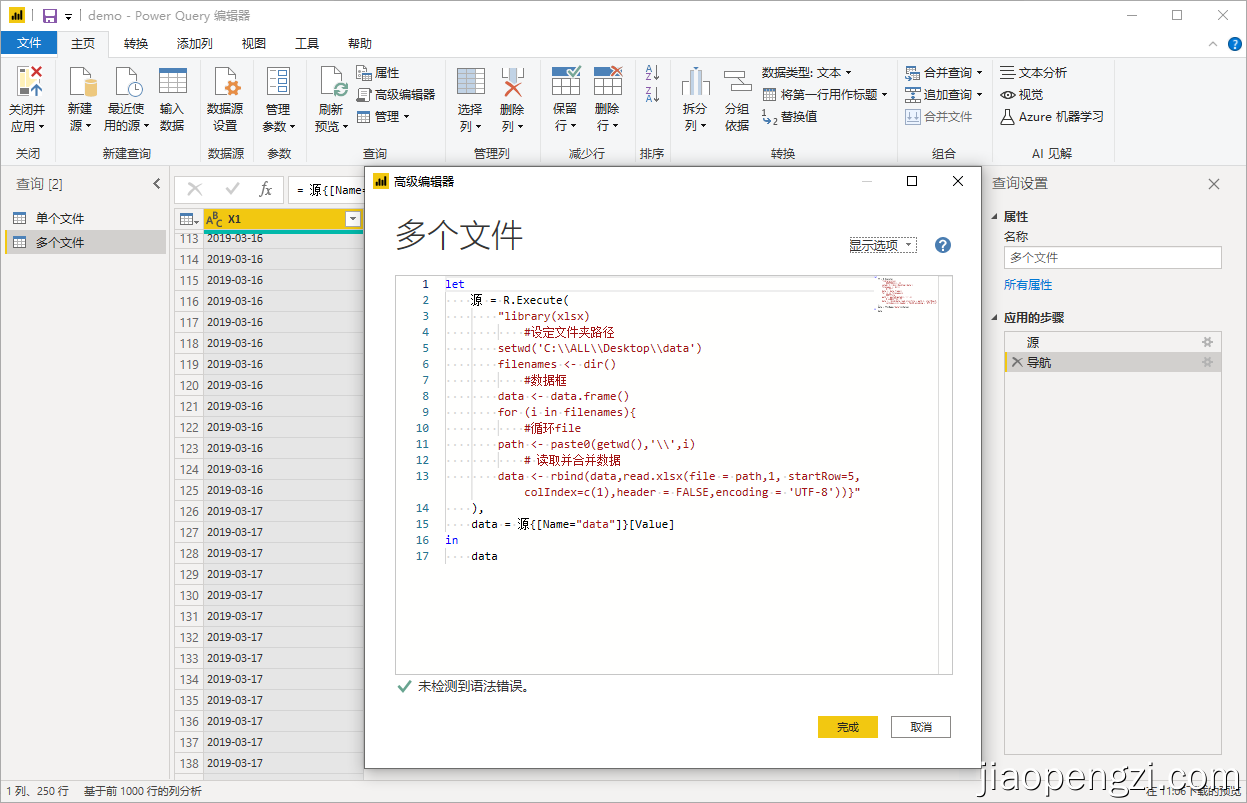
三、总结
1、安装R的xlsx包;
2、注意 read.xlsx 参数的使用;
#官方帮助
read.xlsx(file, sheetIndex, sheetName=NULL, rowIndex=NULL,
startRow=NULL, endRow=NULL, colIndex=NULL,
as.data.frame=TRUE, header=TRUE, colClasses=NA,
keepFormulas=FALSE, encoding="unknown", password=NULL, ...)
3、注意:rowIndex,colIndex的参数可以使向量指定行列,如:c(1,3,4),c(5:10);支持pq中list拼接。
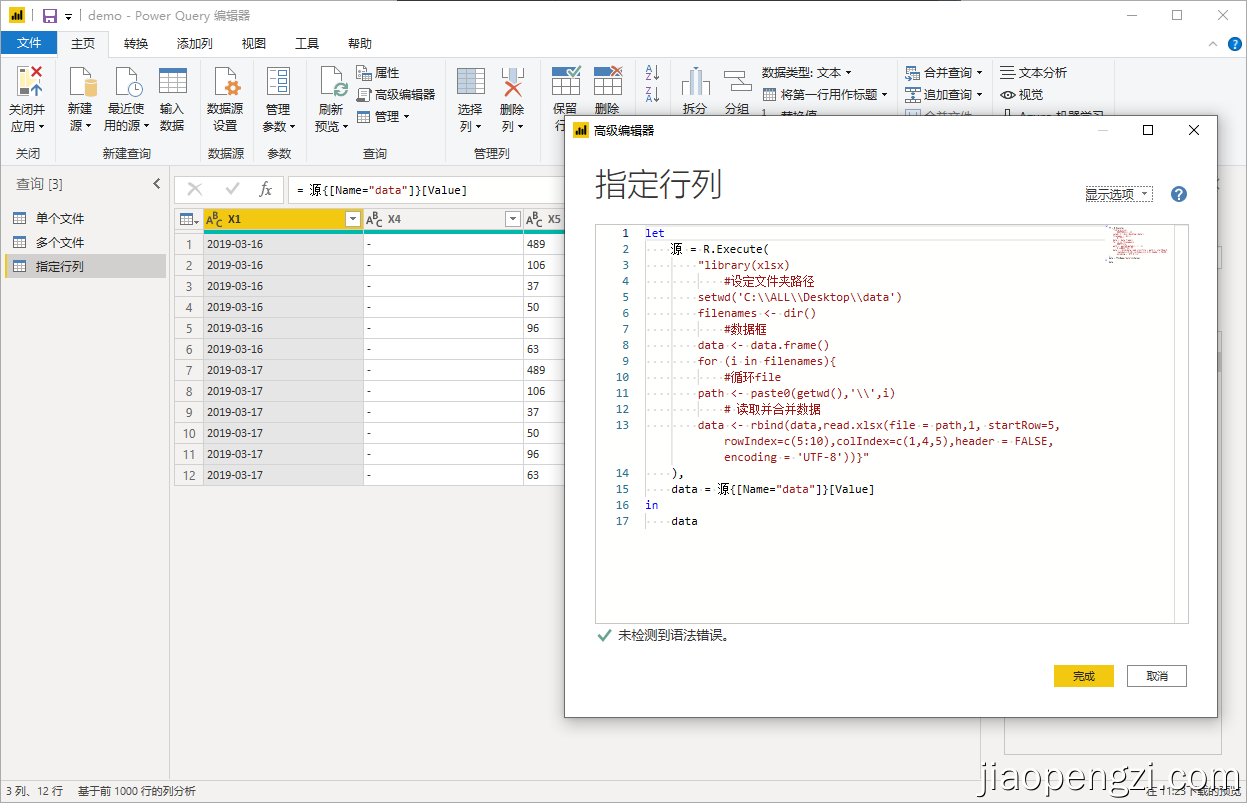
4、在补充一个用ODBC读取的。

by 焦棚子
请点击【立即购买】或者【升级VIP】获得案例附件。



评论