
请在文末下载附件
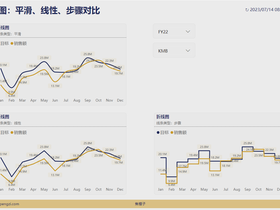
一、效果
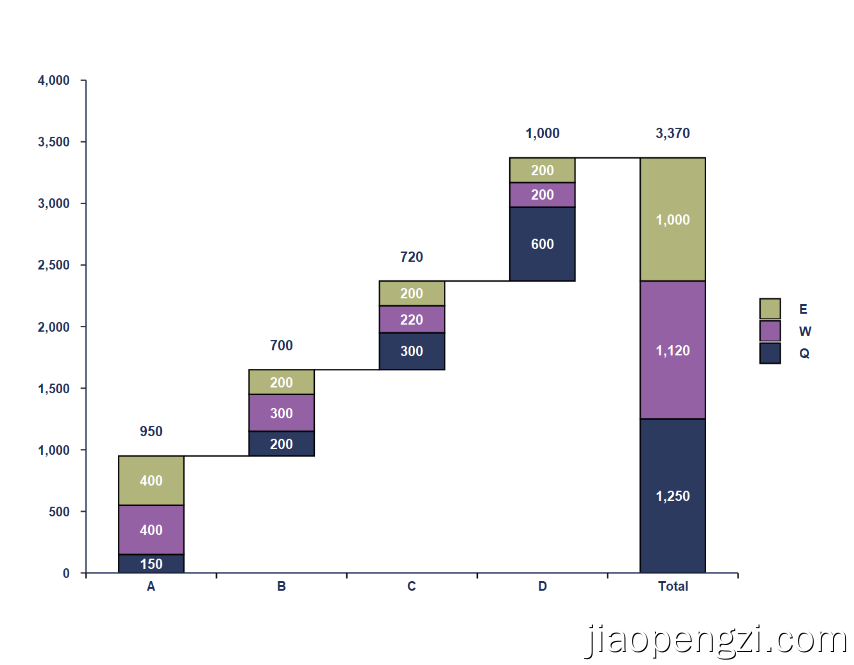
二、data
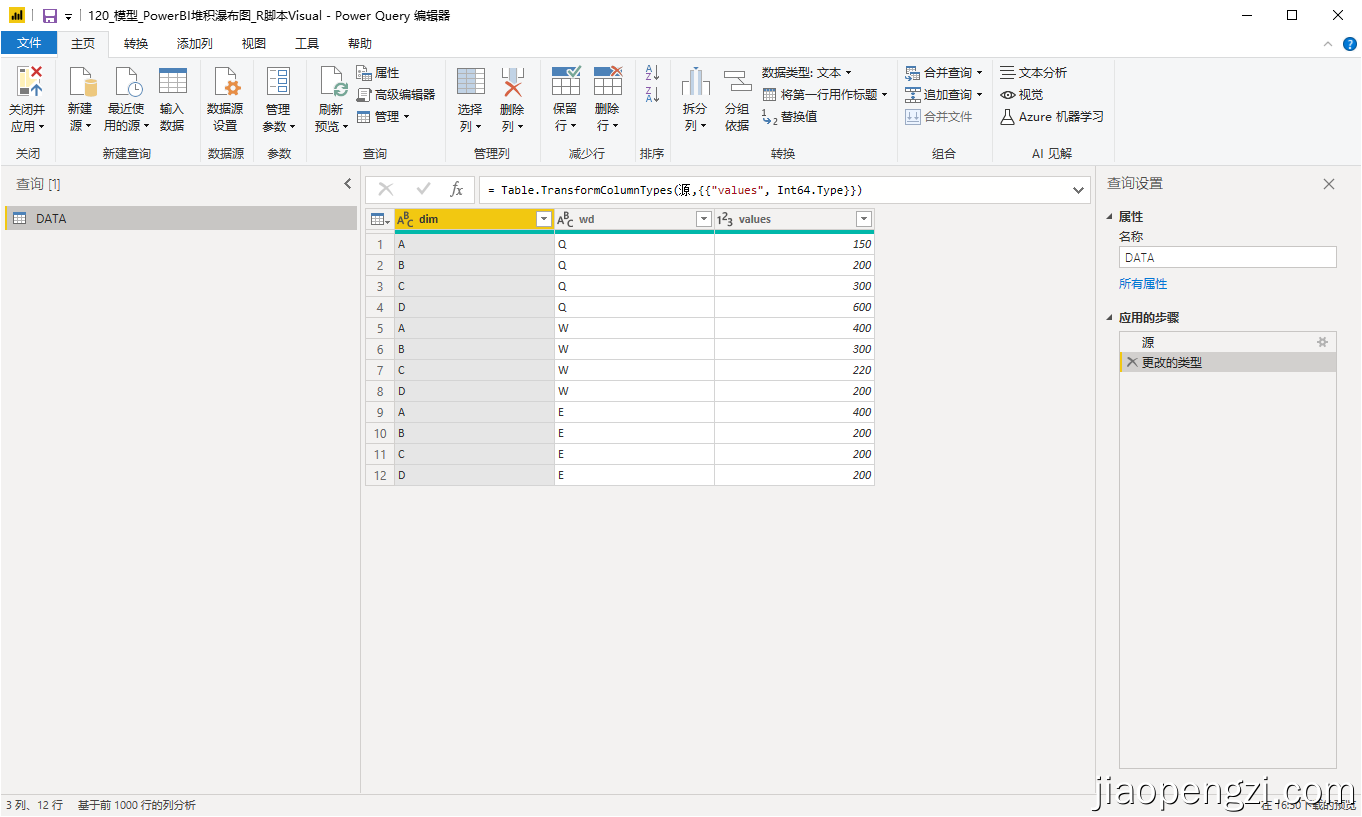
三、添加字段
注意红色框标注地方
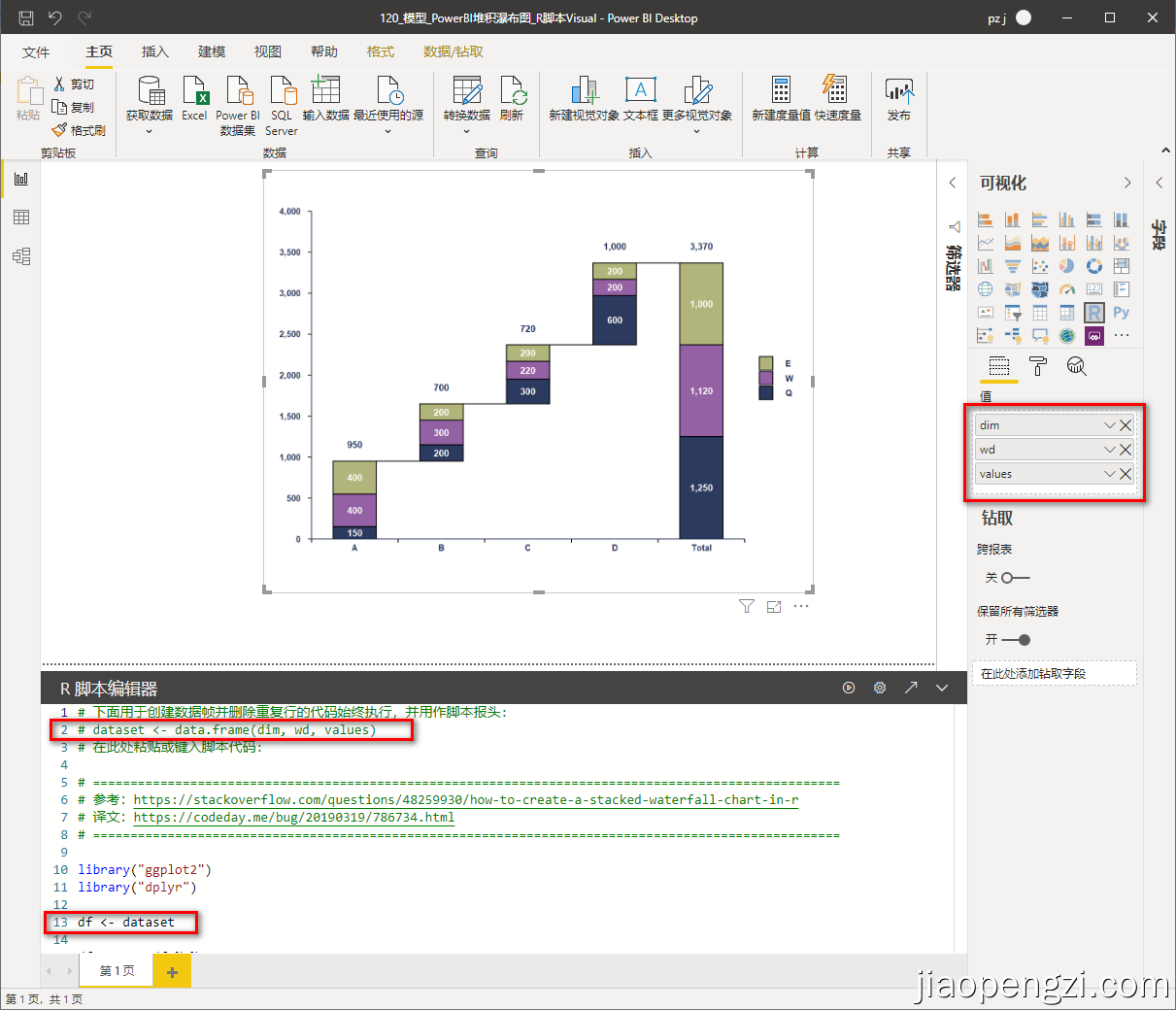
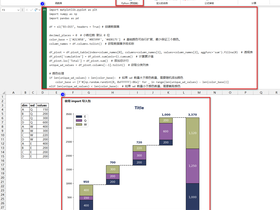
四、code
# 下面用于创建数据帧并删除重复行的代码始终执行,并用作脚本报头:
# dataset <- data.frame(dim, wd, values)
# 在此处粘贴或键入脚本代码:
# ====================================================================================================
# 参考:https://stackoverflow.com/questions/48259930/how-to-create-a-stacked-waterfall-chart-in-r
# 译文:https://codeday.me/bug/20190319/786734.html
# ====================================================================================================
library("ggplot2")
library("dplyr")
df <- dataset
df.tmp <- df %>%
mutate(
dim = factor(dim,
levels = c("A", "B", "C", "D")),
wd = factor(wd,
levels = c("E", "W", "Q"))
) %>%
arrange(dim, desc(wd)) %>%
mutate(end.Bar = cumsum(values),
start.Bar = c(0, head(end.Bar, -1))) %>%
rbind(
df %>%
group_by(wd) %>%
summarise(values = sum(values)) %>%
mutate(
dim = "Total",
wd = factor(wd,
levels = c("E", "W", "Q"))
) %>%
arrange(dim, desc(wd)) %>%
mutate(end.Bar = cumsum(values),
start.Bar = c(0, head(end.Bar, -1))) %>%
select(names(df),end.Bar,start.Bar)
) %>%
mutate(group.id = group_indices(., dim)) %>%
group_by(dim) %>%
mutate(total.by.x = sum(values)) %>%
select(dim, wd, group.id, start.Bar, values, end.Bar, total.by.x)
ggplot(df.tmp, aes(x = group.id, fill = wd)) +
geom_rect(aes(x = group.id,
xmin = group.id - 0.25,
xmax = group.id + 0.25,
ymin = end.Bar,
ymax = start.Bar),
color="black",
alpha=0.95) +
geom_segment(aes(x=ifelse(group.id == last(group.id),
last(group.id),
group.id+0.25),
xend=ifelse(group.id == last(group.id),
last(group.id),
group.id+0.75),
y=ifelse(wd == "E",
end.Bar,
max(end.Bar)*2),
yend=ifelse(wd == "E",
end.Bar,
max(end.Bar)*2)),
colour="black") +
geom_text(
mapping =
aes(
label = ifelse(values < 150,
"",
ifelse(nchar(values) == 3,
as.character(values),
sub("(.{1})(.*)", "\\1,\\2",
as.character(values)
)
)
),
y = rowSums(cbind(start.Bar,values/2))
),
color = "white",
fontface = "bold"
) +
geom_text(
mapping =
aes(
label = ifelse(wd != "E",
"",
ifelse(nchar(total.by.x) == 3,
as.character(total.by.x),
sub("(.{1})(.*)", "\\1,\\2",
as.character(total.by.x)
)
)
),
y = end.Bar+200
),
color = "#213058",
fontface = "bold"
) +
#分类颜色设置
scale_fill_manual(values=c('#ADB175','#8E599F','#213058')) +
# Y轴设置
scale_y_continuous(
expand=c(0,0),
limits = c(0, 4000),
breaks = seq(0, 4000, 500),
labels = ifelse(nchar(seq(0, 4000, 500)) < 4,
as.character(seq(0, 4000, 500)),
sub("(.{1})(.*)", "\\1,\\2",
as.character(seq(0, 4000, 500))
)
)
) +
scale_x_continuous(
expand=c(0,0),
limits = c(min(df.tmp$group.id)-0.5,max(df.tmp$group.id)+0.5),
breaks = c(min(df.tmp$group.id)-0.5,
unique(df.tmp$group.id),
unique(df.tmp$group.id) + 0.5
),
labels =
c("",
as.character(unique(df.tmp$dim)),
rep(c(""), length(unique(df.tmp$dim)))
)
) +
theme(
text = element_text(size = 14, color = "#213058"),
axis.text = element_text(size = 10, color = "#213058", face = "bold"),
axis.text.y = element_text(margin = margin(r = 0.3, unit = "cm")),
axis.ticks.x =
element_line(color =
c("black",
rep(NA, length(unique(df.tmp$dim))),
rep("black", length(unique(df.tmp$dim))-1)
)
),
axis.line = element_line(colour = "#213058", size = 0.5),
axis.ticks.length = unit(.15, "cm"),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
panel.background = element_blank(),
plot.margin = unit(c(1, 1, 1, 1), "lines"),
legend.text = element_text(size = 10,
color = "#213058",
face = "bold",
margin = margin(l = 0.25, unit = "cm")
),
legend.title = element_blank()
)注意:
1、R视觉对象,发布需要pro才行;
2、data的形式和X、Y轴的设置;
3、对R要有所了解。

by焦棚子
请点击【立即购买】或者【升级VIP】获得案例附件。




评论