
请在文末下载附件
一、背景
我们再来谈一谈帕累托在 Power BI 中的度量值写法。我们分别使用以RANKX 和 WINDOW 两个函数为核心写度量值。
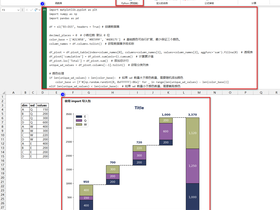
按照惯例,我们先看一下示例结果。
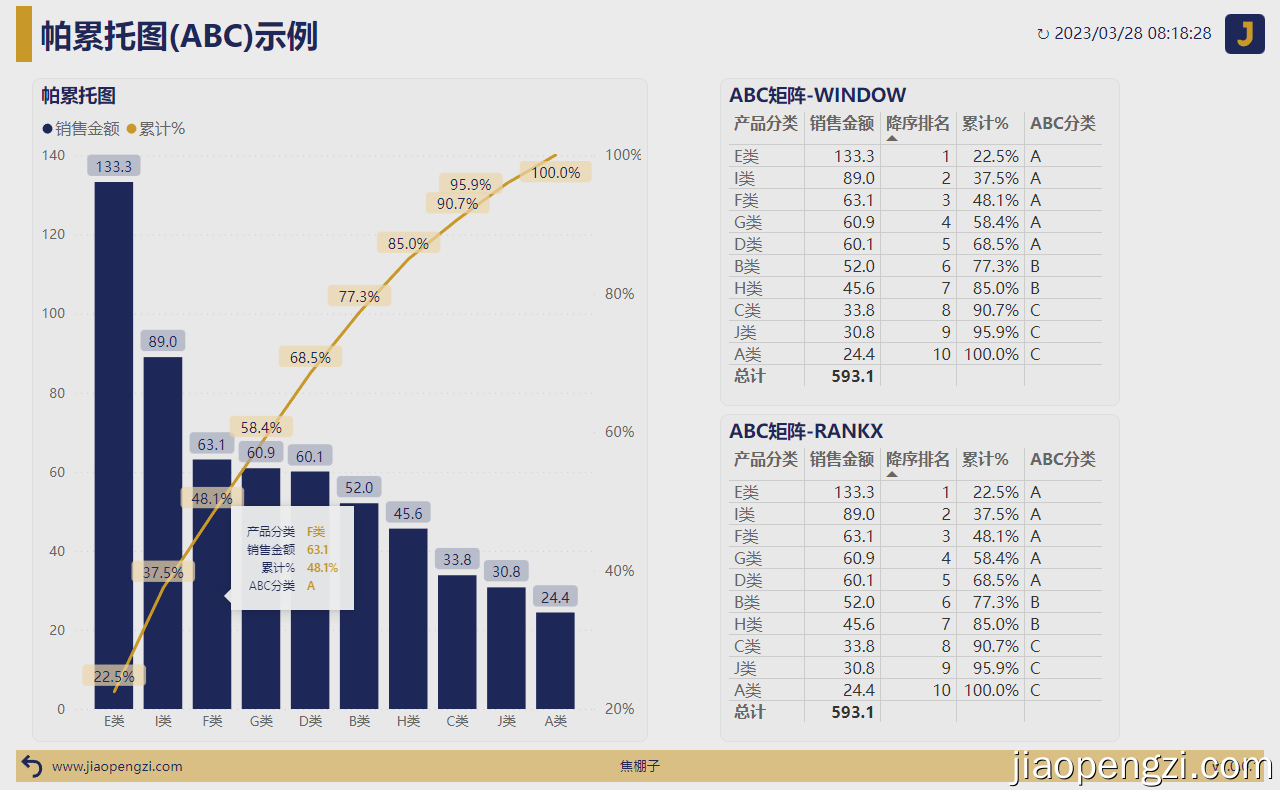
二、模型 & DAX
当前示例,我们只使用到三张表。分别是 T00_产品表、T05_订单子表 以及分类标准计算表 CategoryTable, 关系如下:
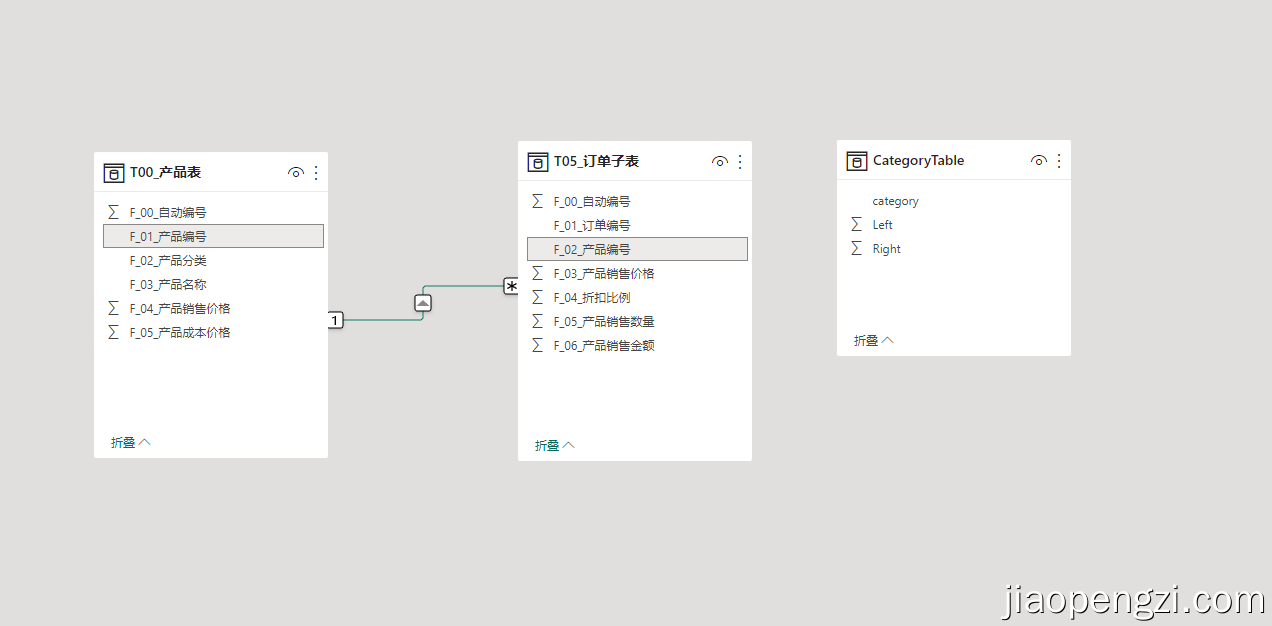
分类标准计算表 CategoryTable 的 DAX,注意区间的开闭规则为:左开右闭。
CategoryTable =
/*区间:左开右闭*/
DATATABLE (
"category", STRING,
"Left", DOUBLE,
"Right", DOUBLE,
{
{ "A", 0, 0.7 },
{ "B", 0.7, 0.85 },
{ "C", 0.85, 1 }
}
)
核心度量值主要是累计占比accumulate%
1、度量值核心 DAX 使用 WINDOW
window_accumulate% =
VAR addTable =
ADDCOLUMNS ( ALLSELECTED ( 'T00_产品表'[F_02_产品分类] ), "@销售金额", [01_销售金额] )
VAR context =
WINDOW ( 1, ABS, 0, REL, addTable, ORDERBY ( [@销售金额], DESC ) )
VAR fenzi =
CALCULATE ( [01_销售金额], context )
VAR fenmu =
CALCULATE ( [01_销售金额], ALL ( 'T00_产品表'[F_02_产品分类] ) )
VAR per =
IF (
ISFILTERED ( 'T00_产品表'[F_02_产品分类] ),
DIVIDE ( fenzi, fenmu, BLANK () ),
BLANK ()
)
RETURN
per
2、度量值核心 DAX 使用 RANKX
rankx_accumulate% =
VAR fenzi =
CALCULATE (
[01_销售金额],
TOPN (
[rankx_rankDesc],
ADDCOLUMNS ( ALL ( 'T00_产品表'[F_02_产品分类] ), "@rank", [rankx_rankDesc] ),
[@rank], ASC
)
)
VAR fenmu =
CALCULATE ( [01_销售金额], ALL ( 'T00_产品表'[F_02_产品分类] ) )
VAR per =
DIVIDE ( fenzi, fenmu, BLANK () )
RETURN
per
三、总结
- 经过我们的测试,使用
WINDOW的效率会略高,建议使用WINDOW为核心的写法。 - 分类的标准,可以自由拓展,根据自身业务去修改。
- 帕累托图的柱子的颜色可以根据分类写对应的 DAX 来设定。
by焦棚子
请点击【立即购买】或者【升级VIP】获得案例附件。




评论